Benefits associated with machine learning are extensive. Industry is increasingly beginning to recognize the wealth of information stored in the data they are collecting. To sort through and analyze all of this data, specialized tools are required to come up with actionable strategies. Often this is done with supervised machine learning algorithms. While these algorithms can be extremely powerful data analysis tools, they require considerable understanding, expertise, and a significant amount of data to use.
Large quantities of data, thousands to millions of data points, ensure that automated machine learning algorithms have enough information on a range of situations it may encounter. However, many real-world applications simply do not occur with enough frequency to accumulate a large enough dataset in a reasonable amount of time. Examples include low volume manufacturing, medical procedures, and disaster events. As a result, these application areas, and others like them, are not able to harness the power of traditional machine learning approaches.
Bayesian Networks (BN) are a widely used machine learning approach. They combine expert knowledge in the form of a network structure and prior probability distribution with Bayesian Statistics. The easily understandable network structure paired with flexible Bayesian Statistical methods lends itself well to investigating behaviors associated with small data sets for machine learning. However, for more complex problems, a method of data simulation or generation should be explored to increase the training set size. Data generation work explored the feasibility of usingKriging and Radial Basis Function models to generate data for four differentBayesian Networks. The goals of the networks were to predict completion time for workers conducting assembly operations, predict the number of errors an assembly worker made, a buyer’s car choice, and the income level of an adult. Examples of the two data generation model types can be seen below.
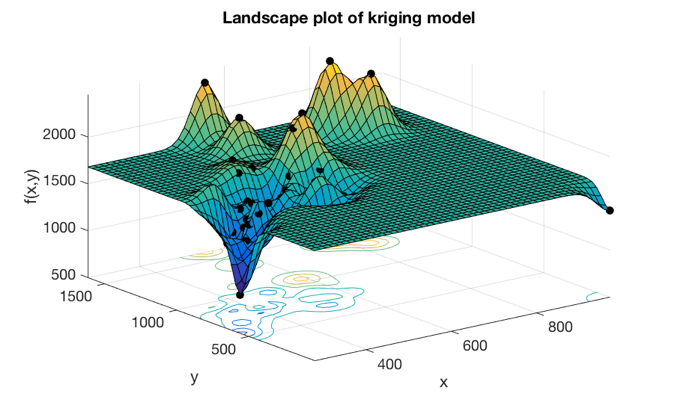
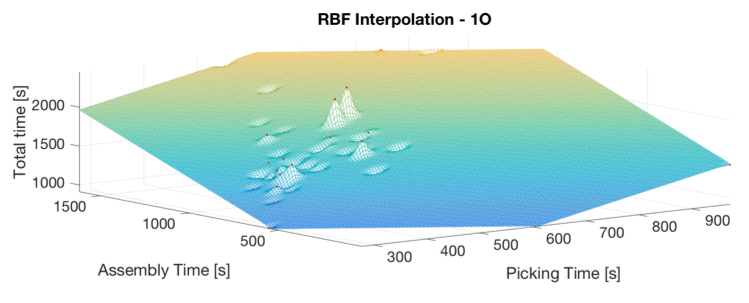
Small amounts of data from each of these datasets were used to train the different BNs. Each of these training datasets were fitted with a Kriging and a Radial Basis Function model. Once models were created, they were randomly sampled to produce a larger dataset for training. While these results were encouraging, further analysis demonstrated the network was biased by priors greatly influenced by the number of data points in a category. In an attempt to solve this issue, PSO was explored as a means to tune network parameters to increase network accuracy. However, results indicate that for a network with a higher degree of parameters like the car choice network there is not sufficient data to use this method or that the method need to be adapted to include more robust metrics. The results suggested that for more complex problems, a method of data simulation or generation should be explored to increase the training set size.
Overall, the exploratory results demonstrate the feasibility of using meta-model generated data and PSO to increase the accuracy of small sample set trained BN. Further developing this method will help underserved areas with access to only small datasets make use of the powerful predictive analytics of ML. Moving forward, future work will continue to refine the data generation methods and look at alternate prior optimization formulations.